
Five Ways to Fix Statistics in Supply Chain Research
The P value debate has revealed that hypothesis testing is in crisis – also in our discipline! But what should we do now? Nature recently asked influential statisticians to recommend one change to improve science. Here are five answers: (1) Adjust for human cognition: Data analysis is not purely computational – it is a human behavior. So, we need to prevent cognitive mistakes. (2) Abandon statistical significance: Academia seems to like “statistical significance”, but P value thresholds are too often abused to decide between “effect” (favored hypothesis) and “no effect” (null hypothesis). (3) State false-positive risk, too: What matters is the probability that a significant result turns out to be a false positive. (4) Share analysis plans and results: Techniques to avoid false positives are to pre-register analysis plans, and to share all data and results of all analyses as well as any relevant syntax or code. (5) Change norms from within: Funders, journal editors and leading researchers need to act. Otherwise, researchers will continue to re-use outdated methods, and reviewers will demand what has been demanded of them.
Leek, J., McShane, B.B., Gelman, A., Colquhoun, D., Nuijten, M.B. & Goodman, S.N. (2017). Five Ways to Fix Statistics. Nature, 551 (2), 557-559. DOI: 10.1038/d41586-017-07522-z
Four Types of Case Study Research Designs
Academics and students often have very different ideas in mind when they talk about case study research. Indeed, case studies in SCM research are not alike and several different case study research designs can be distinguished. A recent article by Ridder (2017), titled The Theory Contribution of Case Study Research Designs, provides an overview of four common approaches. First, there is the “no theory first” type of case study design, which is closely connected to Eisenhardt’s methodological work. The second type of research design is about “gaps and holes”, following Yin’s guidelines. This type of case study design is what can be seen in SCM journals maybe most often. A third design deals with a “social construction of reality”, which is represented by Stake. Finally, the reason for case study research can also be to identify “anomalies”. A representative scholar of this approach is Burawoy. Each of these four approaches has its areas of application, but it is important to understand their unique ontological and epistomological assumptions. A very similar overview is provided by Welch et al. (2011).
Ridder, H.G. (2017). The Theory Contribution of Case Study Research Designs. Business Research, 10 (2), 281-305. https://doi.org/10.1007/s40685-017-0045-z
How to Do a Systematic Literature Review
There has been a recent trend in several management disciplines, including supply chain management, to create knowledge by systematically reviewing available literature. So far, however, our discipline lacked a “gold standard” that guides researchers in this endeavor. The Journal of Supply Chain Management has now published our new article, Durach, Kembro & Wieland (2017): A New Paradigm for Systematic Literature Reviews in Supply Chain Management. Our systematic literature review process follows six steps: (1) develop an initial theoretical framework; (2) develop criteria for determining whether a publication can provide information regarding this framework; (3) identify literature through structured and rigorous searches; (4) conduct theoretically driven selection of literature and a relevance test; (5) develop two data extraction structures, integrate data to refine the theoretical framework, and develop narrative propositions; and (6) explain the refined framework and compare it to the initial assumptions. We believe that these best-practice guidelines, although developed for the SCM discipline, can be used as a blueprint also for adjacent management disciplines.
Durach, C.F., Kembro, J. & Wieland, A. (2017). A New Paradigm for Systematic Literature Reviews in Supply Chain Management. Journal of Supply Chain Management, 53 (4), 67-85. DOI: 10.1111/jscm.12145
Scale Purification
“Scale purification” – the process of eliminating items from multi-item scales – is widespread in empirical research, but studies that critically examine the implications of this process are scarce. In our new article, titled Statistical and Judgmental Criteria for Scale Purification, we (1) discuss the methodological underpinning of scale purification, (2) critically analyze the current state of scale purification in supply chain management (SCM) research, and (3) provide suggestions for advancing the scale purification process. Our research highlights the need for rigorous scale purification decisions based on both statistical and judgmental criteria. We suggest several methodological improvements. Particularly, we present a framework to demonstrate that the justification for scale purification needs to be driven by reliability, validity and parsimony considerations, and that this justification needs to be based on both statistical and judgmental criteria. We believe that our framework and additional suggestions will help to advance the knowledge about scale purification in SCM and adjacent disciplines.
Wieland, A., Durach, C.F., Kembro, J. & Treiblmaier, H. (2017). Statistical and Judgmental Criteria for Scale Purification. Supply Chain Management: An International Journal, 22 (4). DOI: 10.1108/SCM-07-2016-0230
The Conceptual Leap in Qualitative Research
You should all read this interesting article: Approaching the Conceptual Leap in Qualitative Research by Klag & Langley (2013), which is useful for researchers who build theory from qualitative data. Its central message is “that the abductive process is constructed through the synthesis of opposites that [the authors] suggest will be manifested over time in a form of ‘bricolage’.” The authors use four dialectic tensions: deliberation—serendipity, engagement—detachment, knowing—not knowing, social connection—self-expression. One of the poles of each dialectic has a disciplining character, the other pole has a liberating influence: On the one hand, overemphasizing the disciplining poles “may result in becoming ‘bogged down’ in contrived frameworks (deliberation), obsessive coding (engagement), cognitive inertia (knowing) or collective orthodoxy (social connection)”. On the other hand, overemphasizing the liberating poles “can also be unproductive as researchers wait for lightning to strike (serendipity), forget the richness and nuances of their data (detachment), reinvent the wheel (not knowing) or drift off into groundless personal reflection (self-expression)”.
Klag, M., & Langley, A. (2013). Approaching the Conceptual Leap in Qualitative Research. International Journal of Management Reviews, 15 (2), 149-166 DOI: 10.1111/j.1468-2370.2012.00349.x
Deductive, Inductive and Abductive Research in SCM
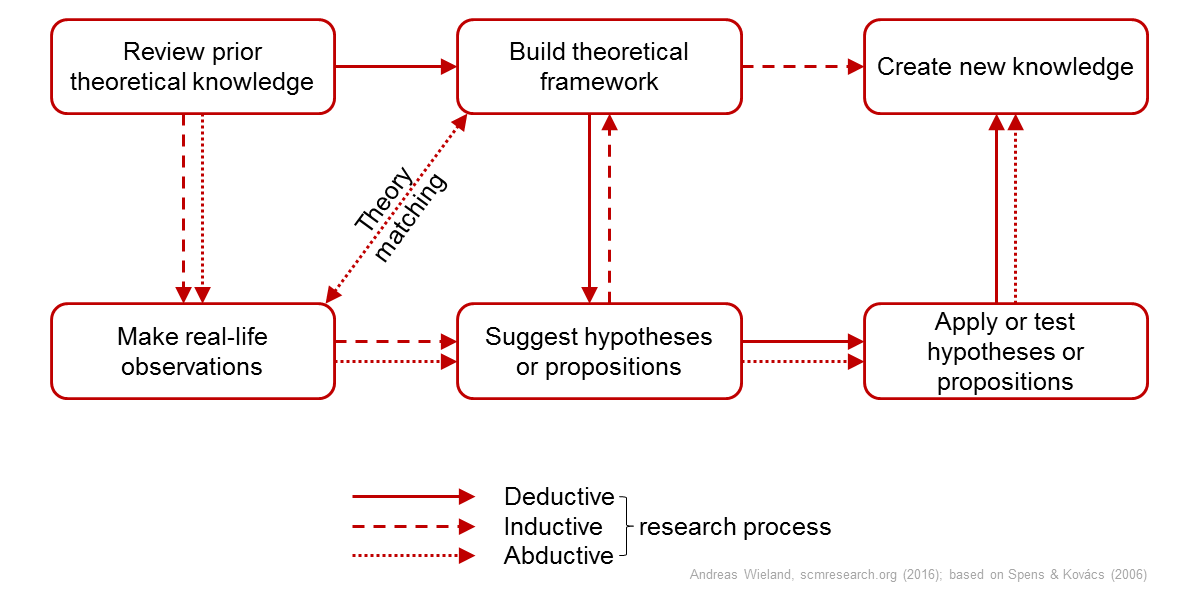 Like it or not: Our discipline is very much dominated by positivism and the application of the scientific method, which assumes that new knowledge can be created by developing and testing theory or, in other words, by induction or deduction. Another type of inference is abduction. Spens & Kovács (2006) present an overview of the deductive, inductive and abductive research processes.
Like it or not: Our discipline is very much dominated by positivism and the application of the scientific method, which assumes that new knowledge can be created by developing and testing theory or, in other words, by induction or deduction. Another type of inference is abduction. Spens & Kovács (2006) present an overview of the deductive, inductive and abductive research processes.
Spens, K., & Kovács, G. (2006). A Content Analysis of Research Approaches in Logistics Research. International Journal of Physical Distribution & Logistics Management, 36 (5), 374-390 https://doi.org/10.1108/09600030610676259
The p-value Debate Has Reached SCM Research
We should not ignore that researchers – in general but also in supply chain management – are not always as properly trained to perform data analysis as they should be. A highly visible discussion is currently going on regarding the prevalent misuses of p-values. For example, too often research has been considered as “good” research, just because the p-value passed a specific threshold – also in the SCM discipline. But the p-value is not an interpretation, it rather needs interpretation! Some statisticians now even prefer to replace p-values with other approaches and some journals have decided to ban p-values. Based on this ongoing discussion, the influential American Statistical Association has now issued a Statement on Statistical Significance and p-values. It contains six principles underlying the proper use and interpretation of the p-value. As a discipline, we should take these principles seriously: in our own research, but also when we review the manuscripts of our colleagues.
Wasserstein, R., & Lazar, N. (2016). The ASA’s Statement on p-values: Context, Process, and Purpose. The American Statistician https://doi.org/10.1080/00031305.2016.1154108
Creating Better Concept Definitions in SCM
I believe we all have already experienced this: The same concept can sometimes be defined in very different ways by different authors. Conceptual clarity would certainly be great, but how can we achieve it? Think, for example, about concepts such as trust, integration or dependence. So, what do we really mean when we are talking about them? In their new article, Recommendations for Creating Better Concept Definitions in the Organizational, Behavioral, and Social Sciences, Podsakoff, MacKenzie & Podsakoff (2016) present four stages for developing good conceptual definitions: Researchers need to (1) “identify potential attributes of the concept and/or collect a representative set of definitions”; (2) “organize the potential attributes by theme and identify any necessary and sufficient ones”; (3) “develop a preliminary definition of the concept”; and (4) “[refine] the conceptual definition of the concept”. For each of these stages, the authors provide comprehensive guidelines and examples which can help supply chain researchers to improve the definitions of the concepts we use.
Podsakoff, P., MacKenzie, S., & Podsakoff, N. (2016). Recommendations for Creating Better Concept Definitions in the Organizational, Behavioral, and Social Sciences. Organizational Research Methods, 19 (2), 159-203 https://doi.org/10.1177/1094428115624965
Multi-Methodological Research in Supply Chain Management
Just like OM research, SCM research is dominated by three research methodologies: (1) analytical modelling research (optimization, computational, and simulation models etc.), (2) quantitative empirical research (surveys etc.), and (3) case study research. There has been a recent trend towards multi-methodological research that combines different methodologies. A new article by Choi, Cheng and Zhao, titled Multi-Methodological Research in Operations Management, investigates this trend. The authors “present some multi-methodological approaches germane to the pursuit of rigorous and scientific operations management research” and “discuss the strengths and weaknesses of such multi-methodological approaches”. The authors make clear that multi-methodological approaches can make our research “more scientifically sound, rigorous, and practically relevant” and “permit us to explore the problem in ‘multiple dimensions’”. However, such research can also be “risky as it requires high investments of effort and time but the final results might turn out to be not fruitful”. Anyhow, as the authors conclude: “no pain, no gain”!
Choi, T., Cheng, T., & Zhao, X. (2015). Multi-Methodological Research in Operations Management. Production and Operations Management DOI: 10.1111/poms.12534
Discriminant Validity – An Update
The AVE–SV comparison (Fornell & Larcker, 1981) is certainly the most common technique for detecting discriminant validity violations on the construct level. An alternative technique, proposed by Henseler et al. (2015), is the heterotrait–monotrait (HTMT) ratio of correlations (see the video below). Based on simulation data, these authors show for variance-based structural equation modeling (SEM), e.g. PLS, that AVE–SV does not reliably detect discriminant validity violations, whereas HTMT identifies a lack of discriminant validity effectively. Results of a related study conducted by Voorhees et al. (2016) suggest that both AVE–SV and HTMT are recommended for detecting discriminant validity violations if covariance-based SEM, e.g. AMOS, is used. They show that the HTMT technique with a cutoff value of 0.85 – abbreviated as HTMT.85 – performs best overall. In other words, HTMT should be used in both variance-based and covariance-based SEM, AVE–SV should be used only in covariance-based SEM. One might be tempted to prefer inferential tests over such heuristics. However, the constrained ϕ approach did not perform well in Voorhees et al.’s study.
Fornell, C., & Larcker, D. (1981). Evaluating Structural Equation Models with Unobservable Variables and Measurement Error. Journal of Marketing Research, 18 (1) https://doi.org/10.2307/3151312
Henseler, J., Ringle, C., & Sarstedt, M. (2015). A New Criterion for Assessing Discriminant Validity in Variance-based Structural Equation Modeling. Journal of the Academy of Marketing Science, 43 (1), 115-135 https://doi.org/10.1007/s11747-014-0403-8
Voorhees, C., Brady, M., Calantone, R., & Ramirez, E. (2016). Discriminant Validity Testing in Marketing: An Analysis, Causes for Concern, and Proposed Remedies. Journal of the Academy of Marketing Science, 44 (1), 119-134 https://doi.org/10.1007/s11747-015-0455-4